
When Google published an insider’s view of its data centre operations, one image showed a branded bicycle that is their employees’ preferred method for getting around the company’s warehouse-sized facilities. Google builds some of the largest data centres in the world, although it considers the precise details to be commercially sensitive. One thing is clear, however; data centres are getting bigger and bigger, and this has major implications for the way they are designed.
Data centres are expanding because they have to handle an ever-increasing workload. From cloud computing applications, streaming video and online gaming to scientific simulations, financial technologies, and the Internet of Things (IoT), a myriad of new applications have significantly increased the traffic that needs to be handled by data centres. In this new cloud computing era, warehouse-scale computers are needed to process user data that no longer reside at a local computer, but are stored in the ‘cloud’.
The hardware to support such a cloud platform consists of thousands of individual computing nodes with their corresponding networking and storage subsystems, power distribution and conditioning equipment, and extensive cooling systems, housed in a building structure that is called a data centre. In today’s operational data centres, the total number of powerful servers can scale to several hundreds of thousands. Therefore, to further emphasize the massive size of this new generation of data centres, people characterise them as ‘warehouse-scale’ or ‘mega’ data centres.
Each and every one of these edge and core data centres processes enormous amounts of traffic and collectively they handle the majority of the entire cloud data. According to Cisco’s Global Cloud Index, the annual global IP traffic passing over data centre networks is expected to exceed 10.4 zettabytes by the end of 2019, with cloud data centre traffic accounting for more than four fifths (83 per cent). Furthermore, it is forecast that, by 2018, nearly four out of five workloads will be processed by these cloud data centres.
In fact, the traffic we see exchanged over telecoms networks is only the tip of the iceberg; there is also a massive increase in internal or intra-data centre network (intra-DCN) traffic. It is worth emphasising that, based on the Cisco’s analysis of the distribution of the entire data centre traffic, about 75 per cent of the traffic is contained within the data centre, while only about 25 per cent actually leaves the data centre – whether travelling to the end user, or as workloads are moved from one data centre to another.
Scaling up operations
One option to scale the capabilities of these data centres to support current and future cloud computing applications is to incorporate more powerful servers based on higher performance processors. Another option to scale up the performance of such data centres is to increase the number of powerful servers that they encompass. In either case, a powerful, ultra-high-capacity intra-DCN is required to connect the servers and switches. To put things into perspective, consider that a data centre with 100,000 servers would require an internal network with more than one petabyte of aggregate bandwidth to support bi-directional communication among all servers!
The main limiting factor of the size of such a data centre, however, may not be the internal network capacity, but the electrical power that is required to sustain its operation. When the number of elements is scaled up into the hundreds of thousands, the consumption of electronic circuits and systems becomes a force to be reckoned with. This is why data centres operators often try to locate new buildings near cheap or renewable sources of electricity, or in regions with cold air for cooling.
A more radical way to scale up the capabilities of data centre operations would be to deploy many, perhaps smaller, data centres, so that they can be located closer to the end users, and each data centre would be less demanding in terms of its individual power and capacity requirements. In this case, and in order for the overall performance to keep scaling with such distributed architecture, there would be a need for significant increases in the available capacity of the communication links that enable these distributed data centres to work together.
Even though most of the traffic stays within the data centre, today, multi-terabit capacities are already required to support data centre interconnect (DCI), which has led to the development of new purpose-built platforms. Considering the predicted increase in IP traffic, in the near future the capacity requirements for the traffic leaving the data centre could become so enormous that current technology might have trouble keeping up.
Just take into account reports that the web-scale data centre players are proposing to build data centres with more than 400,000 servers before the end of this decade. If we also assume that the server interface speeds increase in that time-frame to, say, 25Gb/s and if indeed 15 – 20 per cent of this traffic is now DCI traffic, then the total interconnection capacity across such distributed data centres would soon reach petabit levels.
Attention to architecture
Let’s focus for now on the intra-data centre network. Typically, the servers in each rack within the data centre are connected using a top-of-rack (ToR) switch, while several ToR switches are connected through one or more aggregate switches, and several aggregate switches may be connected using core switches. Currently, such networks are based on high port-density Ethernet switches, typically forming a meshed network based either on the hierarchical ‘fat-tree’ architecture or on a flatter, two-tier spine-leaf architecture (Figure 1). Now imagine how this would look in reality for a data centre with hundreds of thousands of servers.
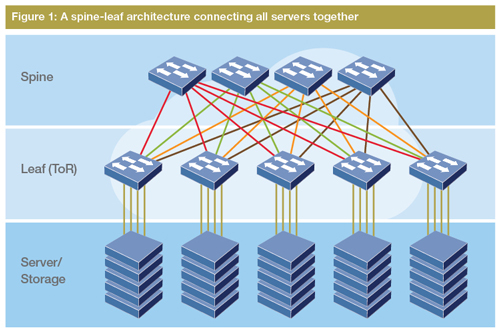
The majority of these data centre networks are based on ethernet, which has seen widespread adoption thanks to its low price, high volumes and technology maturity. So far, electronic ethernet switching has managed to keep up with the requirements in terms of high capacity utilisation and low latency. However, as data centres keep increasing in size, capacity and computing power, this increase will be accompanied by an inevitable increase in power consumption and bandwidth requirements.
This remarkable growth will change the landscape of electrical packet switching by pushing it to its limits in terms of port counts and aggregated bandwidth. Current technology and architecture will soon approach the point at which further scaling would be very costly and environmental unfriendly, due to the bandwidth limitations of electronic circuit technologies, as well as their enormous power consumption. As a result, in order to ensure the long term evolution of data centres, new approaches for data centre networks and switching are needed.
Over recent years, the prevailing industry approach towards upgrading the capacity in data centres consists of introducing optical interfaces – typically based on vertical-cavity surface-emitting laser (VCSEL) technology operating over multimode fibre – while the existing Ethernet switching layer remains the same. Therefore, a major industry and academic effort is under way to identify technologies for cost-effective, power-efficient and high-capacity optical transceivers for the data centre – forecast to be a multi-billion-euro industry of the future.
As data centres grow in capacity terms, they also occupy a much larger physical footprint, so the connections between switches can exceed the distance supported by typical 10 Gigabit Ethernet transceivers. Mega data centres with floor space approaching half a million square feet may require interconnect lengths between 500m and 2km. To scale interconnect speeds beyond 10Gb/s, while also supporting these long distances, transmitting signals in a single lane over a multimode fibre becomes exponentially more difficult. Parallel-lane transmission in the form of ribbon cable or wavelength division multiplexed (WDM) interfaces makes it possible to realise much higher bandwidth interconnection.
The design considerations for short-reach transceivers used in WDM optical interconnects are very different from those used in long-haul WDM transmission links. The choice of wavelength of operation, which could range from 850nm to 1600nm, and the channel spacing for short-reach WDM integrated transceivers will directly impact the cost, size and power consumption of the resulting transceiver module. For example, uncooled transceiver operation is preferred because eliminating the thermo-electric cooler (TEC) reduces power consumption.
In addition, singlemode fibre starts to become more attractive than multimode, not only because it supports longer transmission distances due to elimination of modal dispersion, but also singlemode fibre supports capacity upgrades more easily through WDM without the need to introduce new fibre cables.
For transmission distances up to 2km with signalling rates of less than 10Gbaud, direct modulation with on-off keying is simple, low power and cost-effective, because chromatic dispersion is not a limiting factor in this regime. However, as signalling rates move to 25Gb/s and beyond, to support links at 100G (4x25Gb/s) and 400G (16x25Gb/s, 8x50Gb/s or, eventually, 4x100Gb/s), direct modulation and on-off keying may no longer be the most effective way to support the transmission rate and reach. Novel modulation schemes such as pulse amplitude modulation (e.g. PAM4) and even digital signal processing (DSP) will be needed for certain data centre interconnect formats. Furthermore, in an effort to support further capacity scaling without increasing the costs proportionally, the use of spatial-division multiplexing (SDM) over multi-core fibres is also under consideration.
In addition to all these technical options, a key design parameter for the future optical transceivers will be the material system and the fabrication technology. To achieve the low-cost targets, monolithically integrated WDM/SDM transceivers, incorporated in photonic integrated circuits (PICs), will need to be introduced. The long-discussed silicon-photonics platform is theoretically perfectly suited for large-scale monolithic photonic-electronic integration using mature high-yield CMOS processing techniques, but optical laser sources are still technically challenging to create on silicon. Therefore, other novel alternative concepts that can combine best-in-class components from various material systems, in a heterogeneous hybrid or multi-chip integration approach, could be also considered. Figure 2 shows the amazing progress that has been achieved in the area of photonic integration, indicating that we can expect to see silicon photonics-based transceivers becoming mainstream in a few years’ time.
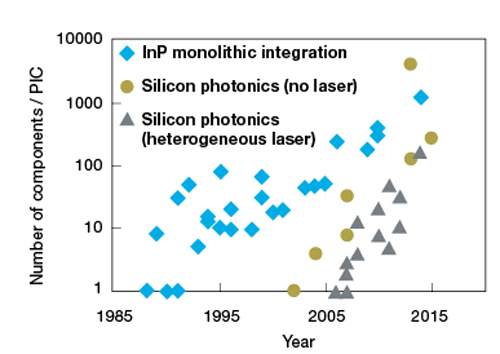
Figure 2: Development of chip complexity measured as the number of components per chip for indium phosphide based photonic integrated circuits (blue) and silicon-based integration distinguishing photonic integrated circuits with no laser (red) or with heterogeneously integrated lasers (green), from: M. J. R. Heck et al. ‘Hybrid silicon photonic integrated circuit technology,’ IEEE J. Sel. Topics in Quantum Electronics, 2013.
Today, no fewer than four different combinations of package style and technology have been proposed for 100G transmission inside the data centre, and the options are even more plentiful at 400G. Nevertheless, in due course the trade-offs between cost, power consumption and complexity will determine the most optimal transmission scheme and transceiver technology to be adopted for the higher transmission speeds.
Of mice and elephants
As the next step, beyond the simple upgrade of point-to-point optical links connecting the ethernet switches within the data centre, optical switching of some type will be introduced gradually. As we mentioned before, current electronic switches will not be able to keep up with the required growth of switching capacity, while maintaining reasonable power consumption and costs. It is expected that by the end of this decade, new power-efficient optical circuit switches will gradually be introduced to support optical bypass of large flows, thus contributing to the reduction of core and aggregate ethernet switches. A number of new data centre network architectures – based on optical switching schemes which have been proposed in recent years can be broadly categorised as hybrid electronic/optical and all-optical.
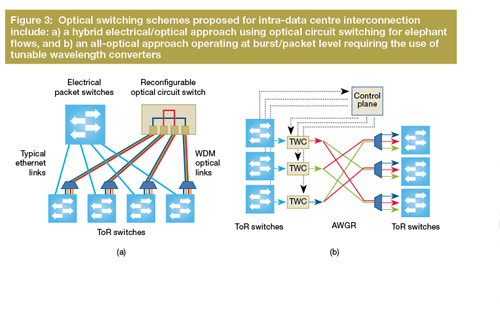
In the first approach – i.e. hybrid electronic/optical schemes – high-volume, high-capacity flows (so-called ‘elephant flows’) are separated from the smaller, low-capacity flows (‘mouse flows’) and switched using two separate, dedicated networks running in parallel. Examples of research projects that have investigated this approach include C-Through, Helios, and OSA (see Further reading). Elephant flows are switched by an optical circuit switch – with reconfiguration times ranging from 10µs to a fraction of a second, depending on the switch technology – while the mice flows continue to be switched in the electronic domain using legacy ethernet-based electronic switches.
Hybrid schemes offer the advantage of allowing an incremental upgrade of an operating data centre equipped with commodity switches, thus reducing the associated capital expenditure. With hybrid schemes, the overall intra-DCN capacity can be significantly increased at reduced cost. Most of these hybrid schemes rely on large-scale fibre/space cross-connects (FXC) or multiple wavelength-selective switches (WSS), based on micro-electro-mechanical systems (MEMs) or liquid-crystal-on-silicon platforms, which are readily available (although not necessarily at the price targets required for this application).
The second approach, comprising all-optical schemes, consists of switching all data with packet or near-packet (i.e. burst) granularity in the optical domain, doing away with electronic switching and optical circuit switching completely (although of course hybrid approaches are possible). A number of research projects have explored this option including, for example, Proteus, Petabit, DOS, LIONS, and CAWG-MIMO (see Further reading), These architectures require ultra-fast optical switching technology based on semiconductor optical amplifiers (SOAs) .
It should be noted that all-optical and packet/burst based approaches proposed to date are still not ready for commercial deployment, and will require the development of new photonic devices, such as ultra-fast optical packet switches and ultra-fast wavelength selective switches. In fact, most of these proposed approaches require complete replacement of commodity electrical switches, meaning that they must provide significantly improved characteristics compared to ethernet switching, in order to justify the cost of the replacement. Therefore, only the partial replacement of ethernet switches with hybrid optical/electrical architectures seems possible in the short term before the end of this decade. But I certainly hope that I will be proved wrong!
The optical networking community recognised early the huge potential that optical technologies have to solve the scaling problems in data centre networks. At OFC 2011, I served as the founding chair of the newly formed ‘Datacom, Computercom and Short Range and Experimental Optical Networks’ subcommittee (now track DSN6 in the OFC 2016 technical programme).
Since that time, the topic of optical communications for data centres has become mainstream and many other major conferences have adapted their coverage accordingly. In addition, over the last couple of years, major funding agencies, including the European Commission, and companies like Facebook, Google, IBM, Intel, Microsoft, and Oracle, have made significant investments into research on the relevant topics. Inevitably, we will soon see some of those developments moving in the commercial world.
For this reason, under the auspices of IIR Telecoms (Informa), we are introducing a new conference dedicated to this topic. The Optical Data Centre Interconnect 2016 (ODCI) conference will take place on 28 June – 1 July 2016 in Nice, France, and is co-located with the 18th annual Next Generation Optical Networking (NGON). The event mission is to enable executives from data centre operators and service providers to exchange ideas, develop expertise and share best practices on this exciting topic, in order to continue taking it forward.
- Dr Ioannis Tomkos is head of the Networks and Optical Communication (NOC) research group at AIT (Athens Information Technology), Greece

